


As enterprises accelerate their move toward cloud-native platforms, their technology environments have grown significantly more distributed, interconnected, and complex. At the same time, expectations for flawless digital experiences continue to rise from both customers and internal stakeholders.
This increasing operational pressure is pushing IT teams to rethink how they detect, diagnose, and prevent issues across their environments. The real answer to addressing this challenge is observability.
In this blog, we’ll explain what observability is and how it helps Nordic enterprises stay resilient, compliant, and competitive.
What is Observability?
Gartner defines observability as the ability to understand what is happening inside a system based on the external data released by that system.
The idea isn’t new. it comes from control theory, introduced by Rudolf Kalman(Electrical engineer and mathematician), where a system is considered observable if its internal state can be accurately inferred from its external outputs.
During the 2010s, Engineers needed a way to infer what was happening across hundreds of interdependent microservices without directly inspecting each one. This need pushed observability to the forefront of modern software engineering.
In today’s IT context, observability is the ability to reconstruct the state and health of a software system by analysing the telemetry it emits.
The Three Pillars of Observability
Traditionally, observability is described through three core telemetry types: logs, metrics, and traces. Each provides a different lens into system behaviour.

Metrics
Logs
Traces
Numerical time-series
Structured or unstructured timestamped event records
Request paths across microservices and components
Emitted by applications, OS, and endpoints.
Generated by applications, containers, and components in the infrastructure.
Produced via instrumentation libraries (O-Tel)
Used for performance tracking and threshold-based alerting
Used for even reconstruction and error analsyis
Used to map the entire request paths in the infrastructure.
Metrics
Logs
Traces
Traces map the end-to-end execution path of requests as they propagate through distributed systems. They reveal service dependencies, latency hotspots, and bottlenecks that aren’t visible through metrics or logs alone.
While these three pillars form the backbone of most observability strategies, they are no longer sufficient on their own for today’s complex environments.
Modern systems require correlation across multiple signal types, enriched context (topology, user behaviour, deployment metadata), and AI-driven analytics to detect emergent patterns that cannot be spotted through isolated telemetry.
The future of observability is about connecting the right data to understand system behaviour at scale.
How Is Observability Different from Monitoring?
Observability is often confused with traditional approaches like Application Performance Monitoring (APM) and Network Performance Management (NPM). While they sit in the same ecosystem, they solve different problems. Monitoring answers predefined questions.
Observability helps you uncover the questions you didn’t know you needed to ask. Monitoring works well for small, stable, monolithic environments where system behaviour is predictable and failure modes are limited. In those cases, metric-based monitoring is usually enough to give a reasonable picture of system health.
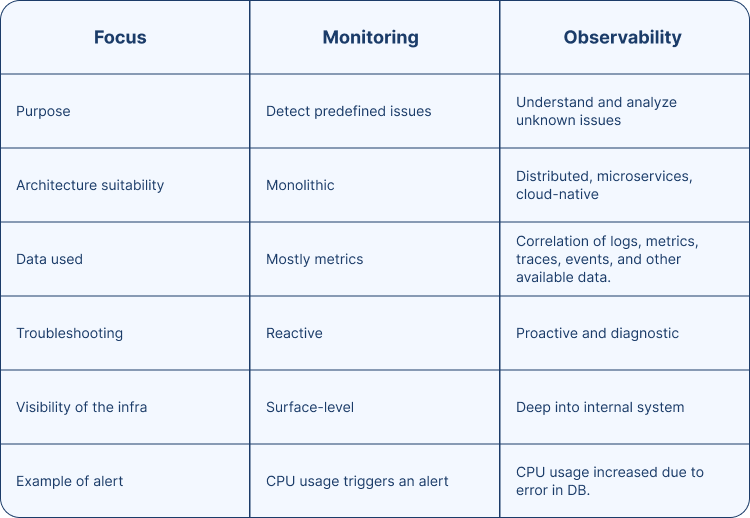
Focus
Monitoring
Observability
Purpose
Architecture suitability
Data used
Troubleshooting
Visibility of the infra
Example of alert
Practical Use Cases for Nordic Enterprises
Modern Nordic enterprises operate in some of the world’s most digitally mature environments with high cloud adoption, strict compliance requirements, and a strong expectation of reliability. In such a landscape, observability is essential to stay competitive.
Here are five practical use cases where observability drives success.
1. Honouring SLAs Across Distributed Nordic Infrastructure
Nordic customers expect reliability whether it’s digital banking, e-health services, or transport systems. SLAs in these regions are aggressive, and downtime is both costly and reputationally damaging.
Nordic digital infrastructures are spread across multiple regions, hybrid clouds, sovereign cloud zones, and remote edge locations. Maintaining SLAs across such a spread requires more than uptime checks.
Observability enables enterprises to keep their promises by:
- Detecting latency spikes before they break SLAs
- Reducing MTTR dramatically with precise, trace-based root-cause identification
- Maintaining consistent uptime across distributed regions and cloud zones.
- Providing real-time visibility into cross-service dependencies, preventing cascading failures
2.Meeting Strict Regulatory and Compliance Requirements
Nordic enterprises are subject to some of the most stringent operational resilience and data governance regulations globally. Regulations such as GDPR, DORA and NIS2, along with each country’s regulations, require organizations to show that their systems stay available, trackable and resilient at all times.
In this complex regulatory environment, observability plays a critical role in helping enterprises achieve and maintain compliance, both directly and indirectly. Take Swedbank’s 850M SEK fine as a case in point.
The penalty was issued not for the downtime itself, but for internal control failures that allowed an IT issue to affect nearly a million customers. Proper observability could have provided the controls, visibility, and proactive monitoring necessary to detect and prevent this issue from escalating into a major incident.
EUs DORA pushes this further. Institutions must detect incidents in real time, trace critical transactions from end to end and report major disruptions within strict timelines. They also need to meet defined RTO and RPO targets and prove that failovers, recovery plans and change processes actually work.
With observability, enterprises gain:
- Immutable logs with full event lineage
- Distributed traces proving how data moves across services
- Forensic-level visibility for post-incident analysis
- Clear evidence of data access, latency thresholds, and policy enforcement
3. Enabling High-Velocity DevOps Without Breaking Production
Every team strives to increase the velocity of their deployments while ensuring stability. This expectation isn’t unique to the Nordics. However, as deployment frequency rises, so does the blast radius of potential failures.
When something goes wrong, the impact can spread quickly across systems and users. Modern observability provides the critical visibility needed to mitigate these risks and enable high-velocity DevOps practices without sacrificing reliability.
Modern observability enables:
- Deployment-aware telemetry (linking code releases to performance changes)
- Real-time anomaly detection immediately after releases
- Automated rollbacks triggered by SLO violations
- Continuous verification of microservices and APIs
With these capabilities, observability helps teams move faster by removing guesswork and enabling faster feedback loops in production.
Teams can deploy with confidence, knowing they have the tools to detect, isolate, and resolve issues quickly.
4. Enhancing Cybersecurity
Nordic enterprises are increasingly targeted by sophisticated threat actors. Sweden alone accounted for 49.52% of ransomware attacks in the region, with Norway and Denmark following at 16.19% each.
Alongside these attacks, Advanced Persistent Threats (APTs) are also on the rise, making the cybersecurity landscape in the Nordics particularly challenging.
Ransomware and APTs are stealthy and move slowly, often goes undetected for months or even years while they silently infiltrate and maintain a foothold within enterprise networks. These threats wait for the right moment to strike, causing maximum disruption or accessing sensitive data.
Observability allows enterprises to detect suspicious behaviours that traditional EDR alone might miss, offering an additional layer of defense.
How observability integrates with cybersecurity
- Faster Mitigation: By providing real-time insights, observability helps security teams respond and mitigate threats quicker.
- Comprehensive Data Correlation: It correlates data across systems (IDS, WAF, EDR etc) to spot hidden threats like lateral movement.
- Anomaly-based Alerts: It triggers alerts based on behavioral anomalies (latency spikes), not just predefined signatures.
- Forensic Investigation: It traces threats post-attack, aiding quick root cause analysis.
For more info: HYPR GUARD
5.Enhancing Customer Experiences in Digital-First Economies
Users now expect instant, seamless experiences, and slow-loading web pages or lagging services can quickly lead to customer churn. For B2C enterprises in the highly competitive Nordic market, delivering a fast, responsive digital experience is essential.
Observability directly impacts customer satisfaction by:
- Identifying UX-impacting issues before users report them
- Ensuring low-latency, high-availability digital experiences
- Identify which backend operations impact front-end experience
- Quantify the experience impact of network hops, caching layers, API gateways
Achieve Complete Observability with HYPR Vision
Building your own observability tools or testing multiple vendors that only address isolated aspects of the puzzle isn’t a viable option for modern enterprises. What you need is a solution that provides comprehensive visibility across all your systems, offers quick and actionable insights, and delivers both technical and business outcomes without delay.
HYPR Vision from Observata does just that. Powered by Elastic, it offers a comprehensive observability platform that covers your entire infrastructure.
With credit-based pricing, you won’t face any surprise costs, and everything is customized specifically for the unique needs of Nordic enterprises. Plus, we offer free migration to ensure a smooth and efficient transition.
Take control of your system’s performance and security today.
Contact us to learn how HYPR Vision can provide the observability your enterprise needs to stay ahead.








